footer, not aside.HTML doesn’t provide a huge number of elements for us to work with. The selection available is more like that of a corner store than a Walmart.
We have paragraphs, lists, and headlines but we don’t have events, news stories, or recipes. HTML gives us an element for marking up a string as an abbreviation, but it doesn’t give us an element for marking up a number as a price.
Clearly, this limitation hasn’t been a show-stopper; just look at the amazing variety of websites out there. Even though HTML might not provide a specific element for marking up a particular piece of content, it provides just enough flexibility to be “good enough.”
To paraphrase Winston Churchill, HTML is the worst form of markup except all the others that have been tried.
Other markup languages allow you to invent any element you want. In XML, if you want an event element or a price element, you just go right ahead and create it. The downside to this freedom is that you then have to teach a parser what event or price means. The advantage to HTML’s limited set of elements is that every user agent knows about every element. Browsers have a built-in knowledge of HTML. That wouldn’t be possible if we were allowed to make up element names.
HTML provides a handy escape clause that allows web designers to add more semantic value to elements: the class attribute. This attribute allows us to label specific instances of an element as being a special class or type of that element. The fact that browsers don’t understand the vocabulary we use in our class attributes doesn’t affect the rendering of our documents.
If, at this point, you’re thinking “Wait a minute; aren’t classes for CSS?” then you’re half right. The CSS class selector is one example of a technology that makes use of the class attribute but it isn’t the only reason for using classes. Classes can also be used in DOM Scripting. They can even be used by browsers if the class names follow an agreed convention, as is the case with microformats.
Microformats are a set of conventions which are agreed upon by a community. These formats use the class attribute to plug some of the more glaring holes in HTML: hCard for contact details, hCalendar for events, hAtom for news stories. Because there is a community consensus on what class names to use, there are now parsers and browser extensions that work with those specific patterns.
Microformats are limited by design. They don’t attempt to solve every possible use case. Instead, they aim for the “lowhanging fruit.” They solve 80% of the use cases with 20% of the effort. Deciding what qualifies as “low-hanging fruit” is pretty straightforward: Just look at what kind of content people are already marking up. In other words, pave the cowpaths.
Sound familiar? Microformats and HTML5 are built on very similar philosophies. In fact, the way I described microformats—conventions agreed upon by a community—could just as easily be applied to HTML5.
The way that the microformats process has been used as a template for developing HTML5 isn’t to everyone’s taste. While the 80/20 rule is good enough for the rough ’n’ ready world of class names, is it really good enough for the most important markup language in the world?
Some people feel that HTML needs to be infinitely extensible. That means it isn’t enough to provide solutions to the majority of use cases; the language must provide a solution to any possible use case.
Perhaps the most eloquent argument for this kind of extensibility came from John Allsopp in his superb A List Apart article, “Semantics in HTML5” (http://www.alistapart.com/articles/semanticsinHTML5):
We don’t need to add specific terms to the vocabulary of HTML, we need to add a mechanism that allows semantic richness to be added to a document as required.
Technologies already exist to do just that. RDFa allows authors to embed custom vocabularies within HTML documents. But unlike microformats—which simply use an agreed set of class names—RDFa uses namespaces to allow an infinite variety of formats. So where a microformat might use markup such as <h1 class="summary">, RDFa would use <h1 property="myformat:summary">.
There’s no doubt that RDFa is potentially very powerful, but its expressiveness comes at a price. Namespaces introduce an extra layer of complexity that doesn’t sit well with the relatively simple nature of HTML.
The namespace debate isn’t new. In a blog post from a few years back, Mark Nottingham mused on the potentially destructive side-effects (http://www.mnot.net/blog/2006/04/07/extensibility):
What I found interesting about HTML extensibility was that namespaces weren’t necessary; Netscape added blink, MSFT added marquee, and so forth. I’d put forth that having namespaces in HTML from the start would have had the effect of legitimising and institutionalising the differences between different browsers instead of (eventually) converging on the same solution.
Rather than infinite extensibility, that’s a powerful argument for a limited vocabulary based on community consensus.
HTML5 will probably ship with some kind of method for extending its native semantics. The class attribute is still in there of course, so microformats will continue to work as they always have. HTML5 might be altered to become compatible with RDFa, or it might use its own “microdata” vocabulary.
In either case, such extensibility will probably be of very little interest to most web designers. What really matters are the native semantics, agreed upon by a community and implemented by browser vendors.
HTML5 introduces a handful of new inline elements to augment our existing arsenal of span, strong, em, abbr, et al. Oh, and we don’t call them “inline” anymore. Instead, they describe “text-level semantics.”
markWhen browsing a list of search results, you’ll often see the search term highlighted within each result. You could mark up each instance of the search term with a span element, but span is a semantically meaningless crutch, good for little more than hanging classes off for styling.
You could use em or strong but that wouldn’t be semantically accurate; you don’t want to place any importance on the search term, you simply want it to be highlighted somehow.
Enter the mark element:
<h1>Search results for 'unicorn'</h1>
<ol>
<li><a href="http://clearleft.com/">
Riding the UX <mark>unicorn</mark>
across the rainbow of the web.
</a></li>
</ol>The mark element doesn’t attach any importance to the content within it, other than to show that it’s currently of interest. As the specification says, mark denotes “a run of text in one document marked or highlighted for reference purposes, due to its relevance in another context.”
The mark element is permitted in contexts other than search results, but I’m damned if I can think of a single such example.
timehCalendar is one of the most popular microformats because it scratches a very common itch: marking up events so that users can add them straight to their calendar.
The only tricky bit in hCalendar is describing dates and times in a machine-readable way. Humans like to describe dates as “May 25th” or “next Wednesday” but parsers expect a nicely-formated ISO date: YYYY-MM-DDThh:mm:ss.
The microformats community came up with some clever solutions to this problem, such as using the abbr element:
<abbr class="dtstart" title="1992-01-12">
January 12th, 1992
</abbr>If using the abbr element in this way makes you feel a little queasy, there are plenty of other ways of marking up machine-readable dates and times in microformats using the class-value pattern. In HTML5, the issue is solved with the new time element:
<time class="dtstart" datetime="1992-01-12">
January 12th, 1992
</time>The time element can be used for dates, times, or combinations of both:
<time datetime="17:00">5pm</time>
<time datetime="2010-04-07">April 7th</time>
<time datetime="2010-04-07T17:00">5pm on April 7th</time>You don’t have to put the datetime value inside the datetime attribute—but if you don’t, then you must expose the value to the end user:
<time>2010-04-07</time>meterThe meter element can be used to mark up measurements, provided that those measurements are part of a scale with minimum and maximum values.
<meter>9 out of 10 cats</meter>You don’t have to expose the maximum value if you don’t want to. You can use the max attribute instead:
<meter max="10">9 cats</meter>There’s a corresponding min attribute. You also get high, low, and optimum attributes to play with. If you want, you can even hide the measurement itself inside a value attribute.
<meter low="-273" high="100" min="12" max="30"
optimum="21" value="25">
It's quite warm for this time of year.
</meter>progressWhile meter is good for describing something that has already been measured, the progress element allows you to mark up a value that is in the process of changing:
Your profile is <progress>60%</progress> complete.Once again, you have min, max, and value attributes if you want to use them:
<progress min="0" max="100" value="60"></progress>The progress element is most useful when used in combination with DOM Scripting. You can use JavaScript to dynamically update the value, allowing the browser to communicate that change to the user—very handy for Ajax file uploads.
Back in 2005, Google did some research to find out what kind of low-hanging fruit could be found on the cowpaths of the web (http://code.google.com/webstats/).
A parser looked at over a billion web pages and tabulated the most common class names. The results were unsurprising. Class names such as “header,” “footer,” and “nav” were prevalent. These emergent semantics map nicely to some of the new structural elements introduced in HTML5.
sectionThe section element is used for grouping together thematically-related content. That sounds a lot like the div element, which is often used as a generic content container. The difference is that div has no semantic meaning; it doesn’t tell you anything about the content within. The section element, on the other hand, is used explicitly for grouping related content.
You might be able to replace some of your div elements with section elements, but remember to always ask yourself, “Is all of the content related?”
<section>
<h1>DOM Scripting</h1>
<p>The book is aimed at designers
rather than programmers.</p>
<p>By Jeremy Keith</p>
</section>headerThe HTML5 spec describes the header element as a container for “a group of introductory or navigational aids.” That sounds reasonable. That’s the kind of content I would expect to find in a masthead, and the word “header” is often used as a synonym for masthead.
There’s a crucial difference between the header element in HTML5 and the generally accepted use of the word “header” or “masthead.” There’s usually only one masthead in a page, but a document can have multiple header elements. You can use the header element within a section element, for example. In fact, you probably should use a header within a section. The specification describes the section element as “a thematic grouping of content, typically with a heading.”
<section>
<header>
<h1>DOM Scripting</h1>
</header>
<p>The book is aimed at designers
rather than programmers.</p>
<p>By Jeremy Keith</p>
</section>A header will usually appear at the top of a document or section, but it doesn’t have to. It is defined by its content—introductory or navigational aids—rather than its position.
footerLike the header element, footer sounds like it’s a description of position but, as with header, this isn’t the case. Instead, the footer element should contain information about its containing element: who wrote it, copyright information, links to related content, etc.
That maps quite nicely onto the mental model that web designers have for the word “footer.” The difference is that, whereas we are used to having one footer for an entire document, HTML5 allows us to also have footers within sections.
<section>
<header>
<h1>DOM Scripting</h1>
</header>
<p>The book is aimed at designers
rather than programmers.</p>
<footer>
<p>By Jeremy Keith</p>
</footer>
</section>asideJust as the header element matches the concept of a masthead, the aside element matches the concept of a sidebar. When I say “sidebar,” I’m not referring to position. Just because some content appears to the left or to the right of the main content isn’t enough reason to use the aside element. Once again, it’s the content that matters, not the position.
The aside element should be used for tangentially related content. If you have a chunk of content that you consider to be separate from the main content, then the aside element is probably the right container for it. Ask yourself if the content within an aside could be removed without reducing the meaning of the main content of the document or section.
Pullquotes are a good example of tangentially related content; they’re nice to have, but you can remove them without affecting the comprehension of the main content.
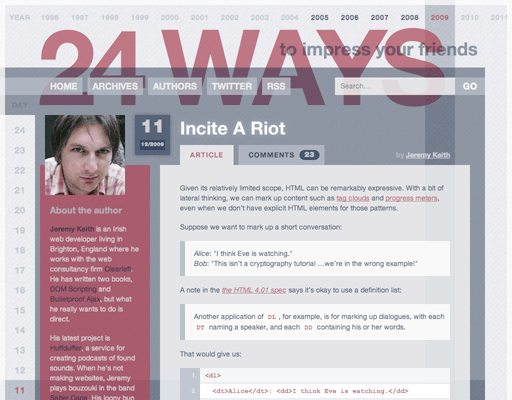
Remember, just because your visual design calls for some content to appear in a sidebar doesn’t necessarily mean that aside is the correct containing element. It’s quite common, for example, to place an author bio in a sidebar. That kind of data is best suited to the footer element—the specification explicitly mentions authorship information as being suitable for footers (fig 5.01).
footer, not aside.Ninety percent of the time, headers will be positioned at the top of your content, footers will be positioned at the end of your content, and asides will be positioned to one side. But don’t get complacent. Stay on your toes and watch out for the remaining ten percent.
navThe nav element does exactly what you think it does. It contains navigation information, usually a list of links.
Actually, I’d better clarify that. The nav element is intended for major navigation information. Just because a group of links are grouped together in a list isn’t enough reason to use the nav element. Site-wide navigation, on the other hand, almost certainly belongs in a nav element.
Quite often, a nav element will appear within a header element. That makes sense when you consider that the header element can be used for “navigational aids.”
articleIt’s helpful to think of header, footer, nav, and aside as being specialized forms of the section element. A section is a generic chunk of related content, while headers, footers, navs, and asides are chunks of specific kinds of related content.
The article element is another specialized kind of section. Use it for self-contained related content. Now the tricky part is deciding what constitutes “self-contained.”
Ask yourself if you would syndicate the content in an RSS or Atom feed. If the content still makes sense in that context, then article is probably the right element to use. In fact, the article element is specifically designed for syndication.
If you use a time element within an article, you can add an optional pubdate Boolean attribute to indicate that it contains the date of publication:
<article>
<header>
<h1>DOM Scripting review</h1>
</header>
<p>A small lighthouse for what has been a long
and sometimes dark voyage for JavaScript.</p>
<footer>
<p>Published
<time datetime="2005-10-08T15:13" pubdate>
3:13pm on October 8th, 2005
</time>
by Glenn Jones</p>
</footer>
</article>If you have more than one time element within an article, only one of them can have the pubdate attribute.
The article element is useful for blog posts, news stories, comments, reviews, and forum posts. It covers exactly the same use cases as the hAtom microformat.
The HTML5 specification goes further than that. It also declares that the article element should be used for self-contained widgets: stock tickers, calculators, clocks, weather widgets, and the like. Now the article element is trying to cover the same use cases as Microsoft’s Web Slices (http://www.ieaddons.com/en/webslices/).
It seems very unintuitive to me that an element named “article” should apply to the construct known as “widget.” Then again, both articles and widgets are self-contained syndicatable kinds of content.
What’s more problematic is that article and section are so very similar. All that separates them is the word “self-contained.” Deciding which element to use would be easy if there were some hard and fast rules. Instead, it’s a matter of interpretation. You can have multiple articles within a section, you can have multiple sections within an article, you can nest sections within sections and articles within articles. It’s up to you to decide which element is the most semantically appropriate in any given situation.
HTML5 gives us the handful of new structural elements described above. They’re especially handy if you’re putting together a conventional site, such as a blog. Most blog designs consist of a header followed by a series of articles, with some tangential content in an aside, and finished off with a footer (fig 5.02).
You can now replace some of your div elements with more semantically precise structural elements. Don’t go overboard, though. Chances are, if you are using a div today, you will still be using a div tomorrow. Don’t swap your div elements for shiny new HTML5 elements just for the sake of it. Think about the content.
These new elements weren’t created just to replace div elements. They provide web browsers with a completely new way of understanding your content.
Previous flavors of markup divided elements into two categories: inline and block. HTML5 uses a more fine-grained approach, dividing elements into a wider range of categories.
Inline elements now have a content model of “text-level semantics.” Many block level elements now fall under the banner of “grouping content”: paragraphs, list items, divs, and so on. Forms have their own separate content model. Images, audio, video, and canvas are all “embedded content.” The new structural elements introduce a completely new content model called “sectioning content.”
It’s possible to create an outline of an HTML document using the heading elements, h1 to h6. Take a look at this markup, for example:
<h1>An Event Apart</h1>
<h2>Cities</h2>
<p>Join us in these cities in 2010.</p>
<h3>Seattle</h3>
<p>Follow the yellow brick road to the emerald city.</p>
<h3>Boston</h3>
<p>That's Beantown to its friends.</p>
<h3>Minneapolis</h3>
<p>It's so <em>nice</em>.</p>
<small>Accommodation not provided.</small>That gives us this outline:
This works well enough. Any content that follows a heading element is presumed to be associated with that heading.
Now look at the final small element. That should be associated with the entire document. But a browser has no way of knowing that. There’s no way of knowing that the small element shouldn’t fall under the heading “Minneapolis.”
The new sectioning content in HTML5 allows you to explicitly demarcate the start and the end of related content:
<h1>An Event Apart</h1>
<section>
<header>
<h2>Cities</h2>
</header>
<p>Join us in these cities in 2010.</p>
<h3>Seattle</h3>
<p>Follow the yellow brick road.</p>
<h3>Boston</h3>
<p>That's Beantown to its friends.</p>
<h3>Minneapolis</h3>
<p>It's so <em>nice</em>.</p>
</section>
<small>Accommodation not provided.</small>Now it’s clear that the small element falls under the heading “An Event Apart” rather than “Minneapolis.”
I can subdivide this content even further, placing each city in its own section:
<h1>An Event Apart</h1>
<section>
<header>
<h2>Cities</h2>
</header>
<p>Join us in these cities in 2010.</p>
<section>
<header>
<h3>Seattle</h3>
</header>
<p>Follow the yellow brick road.</p>
</section>
<section>
<header>
<h3>Boston</h3>
</header>
<p>That's Beantown to its friends.</p>
</section>
<section>
<header>
<h3>Minneapolis</h3>
</header>
<p>It's so <em>nice</em>.</p>
</section>
</section>
<small>Accommodation not provided.</small>That still gives us the same outline:
So far, the new sectioning content isn’t giving us much more than what we could do with previous versions of HTML. Here’s the kicker: In HTML5, each piece of sectioning content has its own self-contained outline. That means you don’t have to keep track of what heading level you should be using—you can just start from h1 each time:
<h1>An Event Apart</h1>
<section>
<header>
<h1>Cities</h1>
</header>
<p>Join us in these cities in 2010.</p>
<section>
<header>
<h1>Seattle</h1>
</header>
<p>Follow the yellow brick road.</p>
</section>
<section>
<header>
<h1>Boston</h1>
</header>
<p>That’s Beantown to its friends.</p>
</section>
<section>
<header>
<h1>Minneapolis</h1>
</header>
<p>It's so <em>nice</em>.</p>
</section>
</section>
<small>Accommodation not provided.</small>In previous versions of HTML, this would have produced an inaccurate outline:
In HTML5, the outline is accurate:
hgroupThere are times when you might want to use a heading element but you don’t want its contents to appear in the document outline. The hgroup element allows you to do just that:
<hgroup>
<h1>An Event Apart</h1>
<h2>For people who make websites</h2>
</hgroup>In this case, the level two heading “For people who make websites” is really a tagline. In an hgroup element, only the first heading will contribute to the outline. The first heading doesn’t necessarily have to be an h1:
<hgroup>
<h3>DOM Scripting</h3>
<h4>Web Design with JavaScript and the Document Object Model</h4>
</hgroup>Some elements are invisible to the generated outline. In other words, it doesn’t matter how many headings you use within these elements, they won’t appear in the document’s outline.
The blockquote, fieldset, and td elements are all immune to the outline algorithm. These elements are called “sectioning roots”—not to be confused with sectioning content.
Because each piece of sectioning content generates its own outline, you can now get far more heading levels than simply h1 to h6. There is no limit to how deep your heading levels can go. More importantly, you can start to think about your content in a truly modular way.
Suppose I have a blog post entitled “Cheese sandwich.” Before HTML5, I would need to know the context of the blog post in order to decide which heading level to use for the title of the post. If the post is on the front page, then it appears after an h1 element containing the title of my blog:
<h1>My awesome blog</h1>
<h2><a href="cheese.html">Cheese sandwich</a></h2>
<p>My cat ate a cheese sandwich.</p>But if I’m publishing the blog post on its own page, then I want the title of the blog post to be a level one heading:
<h1>Cheese sandwich</h1>
<p>My cat ate a cheese sandwich.</p>In HTML5, I don’t have to worry about which heading level to use. I just need to use sectioning content—an article element in this case:
<article>
<h1>Cheese sandwich</h1>
<p>My cat ate a cheese sandwich.</p>
</article>Now the content is truly portable. It doesn’t matter whether it’s appearing on its own page or on the home page:
<h1>My awesome blog</h1>
<article>
<h1>Cheese sandwich</h1>
<p>My cat ate a cheese sandwich.</p>
</article>HTML5’s new outline algorithm produces the correct result:
The fact that each piece of sectioning content has its own outline makes it the perfect match for Ajax. Yet again, HTML5 displays its provenance as a specification for web applications.
Trying to port a piece of content from one document into another introduces some problems. The CSS rules being applied to the parent document will also apply to the inserted content. That’s currently one of the challenges in distributing widgets on the web.
HTML5 offers a solution to this problem in the shape of the scoped attribute, which can be applied to a style element. Any styles declared within that style element will only be applied to the containing sectioning content:
<h1>My awesome blog</h1>
<article>
<style scoped>
h1 { font-size: 75% }
</style>
<h1>Cheese sandwich</h1>
<p>My cat ate a cheese sandwich.</p>
</article>In that example, only the second h1 element will have a font-size value of 75%. That’s the theory anyway. No browsers support the scoped attribute yet.
Therein lies the rub. Before you can start using a new addition to HTML5, you need to consider the browser support for that feature. I have a few strategies to help you get started with HTML5, no matter what the browser support is like. In the next and final chapter, I’d like to share those strategies with you.
Using HTML5 Today